SORTIE-ND
Software for spatially-explicit simulation of forest dynamics |
||
Spatial disperse behaviorsSpatial disperse behaviors rely on the location and size of parent trees to determine the number and placement of seeds. The placement of the seeds is controlled by a probability distribution function. You can choose between the Weibull and lognormal functions. The Weibull function is as follows: 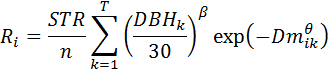 where, 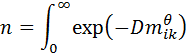 and where:
The lognormal function is as follows: 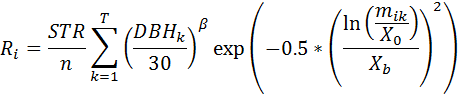 where, 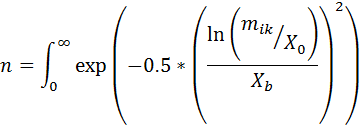 and where:
The maximum distance that seeds are allowed to disperse is the length of the grid in the longest direction, up to a maximum of 1000 meters. Because of the torus shape of the plot, a seed deposited at the very limit of the distance could end up back underneath the parent tree. For this reason, if you are using a very flat dispersal kernel, you may wish to consider a non-spatial disperse method. The normalizer (Equation 3 of Ribbens et al 1994) serves two functions. It reduces parameter correlation between STR and the dispersion parameter (D); and scales the distance-dependent dispersion term so that STR is in meaningful units - i.e. the total # of seedlings produced in the entire seedling shadow of a 30 cm DBH parent tree. |
||
|
FAQ - Contact Us
|
||